Informatique sans serveur: On aime ou pas?

Au cours des dernières années, on a pu constater une augmentation marquée des plateformes sans serveur. Bien que peu de solutions prêtes pour la production ont été lancées, l’écosystème a quand même pris beaucoup de maturité. Vous avez peut-être même des modèles prêts à l’emploi dans votre environnement ou votre pipeline que vous pourriez considérer pour un déploiement sans serveur.
Les architectures sans serveur font en sorte que la logique applicative Web soit traitée indépendamment des serveurs physiques, des machines virtuelles, des conteneurs ou des systèmes d’exploitation. La personne morale propriétaire du système informatique est donc libérée de l’obligation d’acheter, de louer ou encore d’obtenir des serveurs ou des machines virtuelles pour exploiter le code d’arrière-plan. Seuls les processus et le code sont impliqués et les fonctionnalités requises de la part d’un fournisseur peuvent être choisies et agencées selon les besoins. Ses applications dépendent majoritairement d’un BaaS (Backend as a Service) ou d’une FaaS (Function as a Service). Le BaaS réfère à des fournisseurs et des services API, soit internes ou externes, tandis qu’une FaaS peut être décrite comme du code personnalisé, adapté pour répondre à n’importe quel besoin. Grâce à l’informatique sans serveur vous pouvez déployer du code et utiliser les ressources comme si vous déployiez une base de données, un équilibreur de charge ou tout autre service PaaS (Platform as a Service). Le développement de logiciel est facilité par cette souplesse, par l’espace crée par la logique indifférenciée côté serveur ainsi que l’état géré par les fournisseurs infonuagiques. Les ressources d’informatique sans serveur sont mises à l’échelle de façon dynamique pour répondre aux exigences de consommation réelles sans que l’utilisateur soit impliqué ou concerné par les serveurs physiques, les machines virtuelles ou les conteneurs. Le diagramme suivant illustre les responsabilités respectives de chacun.
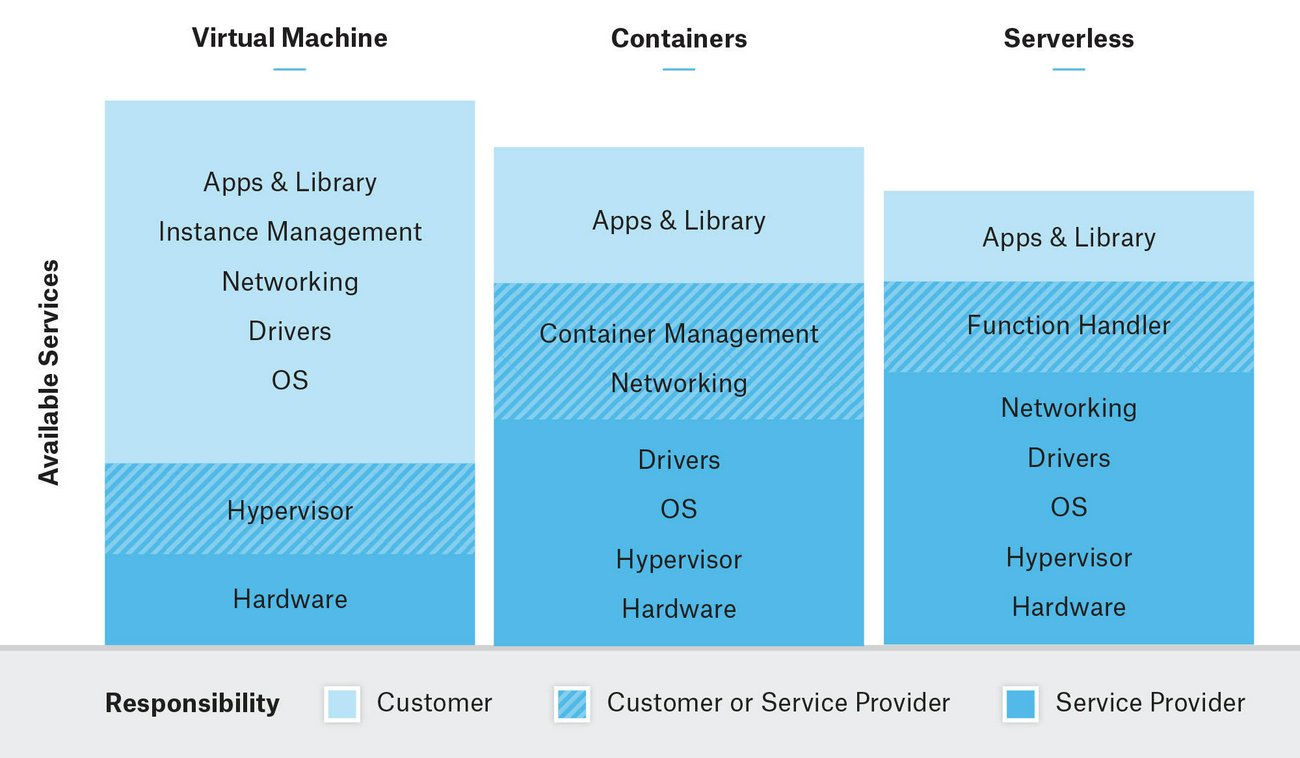
Les différentes formes de PaaS offrent des niveaux variés de souplesse au niveau de l’infrastructure. Comme exemple éloigné d’une PaaS spécialisée, le BaaS (Backend-as-a-Service) a gagné en popularité parmi les développeurs d’applications mobiles au début, puis plus récemment, parmi les développeurs Web qui cherchaient un service infonuagique d’arrière-plan intégré offrant les fonctions essentielles comme le stockage de données, des services de notifications push, le mode utilisateur et l’intégration aux médias sociaux. Ces services peuvent être réutilisés en tant que microservices dans la plupart des types d’applications client-serveur. Avec la récente émergence d’applications Web monopages et d’architectures relatives, le BaaS s’est répandu, même en dehors du développement mobile. Son architecture est semblable à une architecture mobile, mais cible les postes de travail, les courriels et les navigateurs.
Le BaaS, comme forme de PaaS, pourrait être mieux compris dans un contexte d’applications mobiles que les architectures sans serveur qui celles-ci, se définissent mieux comme FaaS (Function [s] — as-a -Service). Avec une FaaS, on peut développer, exploiter et maintenir dans le nuage, certaines fonctionnalités applicatives spécifiques, tout en réduisant notre dépendance à la gestion de services de plateformes, à la gestion des systèmes, aux politiques de mise à l’échelle et autres responsabilités administratives traditionnelles et DevOps. Bien que le BaaS offre un ensemble de règles bien définies et de saisies à réponses connues, une FaaS vous donne les moyens de tout lier, peu importe ce que vous choisissez, incluant même le BaaS. On peut comparer une FaaS à un restaurant de style buffet tandis qu’une PaaS, elle, offrirait un menu fixe. Une FaaS offre une pleine portée de flexibilité suggérée par une architecture sans serveur.
Quand doit-on utiliser une architecture sans serveur ?
- L’architecture sans serveur est la solution idéale pour des modèles d’utilisation imprévisibles nécessitant des mises à l’échelle inattendues de transactions courtes et ponctuelles. Les usages allant avec les applications saisonnières ou épisodiques, comme le soutien aux scripts de diffusion de publicités et le traitement des données entrantes par des capteurs de soumission de contenu orienté utilisateur qui proviennent de l’Ido (Internet des objets), peuvent bénéficier particulièrement d’une architecture sans serveur qui réagit presque instantanément pour répondre aux demandes de mémoire et d’UCT, même si l’application est au repos.
- Des unités de travail discrètes telles que l’informatique orientée événements, les données entrantes de l’Ido, les stream ou files d’attente d’événements kafka, les files d’attente de travail comme SQS ou rabbitmq, ou tout autre type de charge de travail asynchrone, peut tirer avantage d’une architecture sans serveur pour traiter cette information en tant que type d’ETL (ou extracto-chargeur) évolutif.
- Le code et les bibliothèques sans serveur peuvent être exécutés sur le nuage sans qu’il soit nécessaire d’affecter des capacités informatiques à l’avance. Il est donc plus facile de mobiliser des ressources sur demande, au bon moment et au besoin. Les fonctionnalités qui sont requises simultanément peuvent être mises à l’échelle pour répondre aux besoins de capacité en fonction de chaque demande ou d’unité de travail.
- Le délai de lancement d’une application est accéléré par une architecture sans serveur, ce qui permet aux développeurs de se concentrer sur le code et sur les processus plutôt que sur des éléments non différenciés et les surcharges. Le besoin de gérer les ressources traditionnelles est totalement supprimé, ou presque. Le fait d’abolir la surcharge au niveau de l’orchestration et de la gestion fera augmenter, à long terme, votre vitesse de développement.
Quels sont les principaux inconvénients à l’informatique sans serveur ?
- Une architecture sans serveur peut causer l’enfermement à un fournisseur, car il est très difficile de faire passer du code d’un fournisseur infonuagique à un autre ou de concevoir le code pour de multiples nuages.
- Cela peut mener à l’enfermement multiple, ce qui signifie que vos applications sont composées de plusieurs fonctions provenant de différents fournisseurs. Même si cela semble optimal, les problèmes engendrés peuvent être plus gros qu’un simple enfermement à un fournisseur.
- Le fait de dérouler votre propre architecture sans serveur en utilisant des projets de logiciel libre comme OpenWhisk, ajoute, en plus de complexités technologiques, des coûts supplémentaires et des frais généraux. Une approche DIY (Do-it-yourself) vous permet de bâtir une architecture sans serveur selon vos propres conditions, mais ce n’est peut-être pas si évident.
- Une architecture sans serveur est plus coûteuse et moins efficace pour les applications de longue durée qui consomment des ressources de façon constante. Elle est conçue pour être efficace et optimisée pour répondre à de petites requêtes et unités de travail rapidement exécutables.
- L’informatique sans serveur étant encore à ses balbutiements, le débogage, la surveillance, les processus de déploiements CI/CD et les schémas traditionnels peuvent présenter des défis, surtout dans des systèmes complexes multicouches qui proposent des dizaines ou même des centaines de fonctions.
- Étant donné que les services d’informatique sans serveur sont relativement nouveaux dans l’espace, ils peuvent comporter des facteurs de risques jusqu’à maintenant inconnus ou facilement comptabilisés.
Le terme « sans serveur » est ironique, en quelque sorte, puisque des serveurs sont évidemment impliqués ; l’informatique sans serveur est cependant passionnante, car elle permet de percer le code et de simplifier la complexité des applications non monolithiques. Cette technologie offre un environnement infonuagique où les ressources sont affectées, selon l’usage, de façon quasi instantanée. En s’occupant de la surcharge d’orchestration, elle réduit le délai de lancement et lorsqu’elle est utilisée à bon escient, elle peut vous faire épargner considérablement. Une architecture sans serveur offre probablement la forme la plus pure d’infonuagique, car elle permet aux clients d’obtenir exactement ce dont ils ont besoin, au bon moment. Pour toutes questions, ou si vous aimeriez que l’un de nos experts effectue une évaluation de votre architecture, n’hésitez pas à nous contacter.
Faites-nous part de vos réflexions !
 À propos de l’auteur — Donald Donovan
À propos de l’auteur — Donald Donovan
Donald est un architecte de solution avec un intérêt marqué pour les données et pour les applications technologiques pratiques, leurs effets sur le comportement et sur les interactions humaines, ainsi que la façon dont elles évoluent face aux nouveaux moyens de communication et récentes technologies. Donald a travaillé sur de nombreux projets allant de l’analyse de la performance, à l’évaluation d’application, à l’analyse des données et aux concepts architecturaux ; il a su démystifier pour les clients, les tenants et aboutissants des différentes technologies.