Télédétection, pipelines de données, Kubernetes et réseaux neuronaux dans le domaine de l’écologie.

Le dépôt GitHub pour ce projet se trouve ici https://github.com/TristansCloud/YellowstonesVegitiation
« La télédétection est l’acquisition d’information à propos d’un objet ou d’un phénomène sans entrer en contact physique avec l’objet ou le phénomène… [et] se réfère généralement à l’utilisation de technologies de satellite ou de détecteurs sur les aéronefs. » Autrement dit, c’est la collecte de données des paresseux ! Le type de collecte de données où l’on balaie le monde entier quotidiennement. La télédétection nous apporte un flot continu de données à propos de l’état du monde, révolutionnant au passage des domaines comme l’agriculture, la défense internationale, la surveillance environnementale, la gestion de crise, les télécommunications, les prévisions météo, la lutte contre les incendies et bien d’autres. Toute application pouvant se placer dans un contexte spatial a probablement bénéficié des avancées dans la télédétection. C’est grâce à la technologie de télédétection que mon domaine, l’écologie, peut surveiller les changements dans la couverture forestière et la prolifération d’algues dangereuses à l’échelle planétaire, nous pouvons aussi estimer les populations d’espèces en voie de disparition et désigner les zones les plus importantes pour le fonctionnement des écosystèmes et qu’il faut protéger.
De mon côté, je réfléchis depuis quelque temps à ce que la télédétection pourrait apporter à mes propres intérêts de recherche. J’étudie les procédés qui favorisent les modifications évolutives dans une sphère se situant à l’intersection entre la biologie évolutive et l’écologie que l’on appelle « dynamique éco-évolutive ». Je m’intéresse particulièrement aux éléments inertes qui structurent un écosystème : de quelle manière le croisement entre le terrain, le climat, la géochimie et la perturbation humaine (c’est un élément vivant, certes, mais un cas à part) déterminera-t-il les organismes qui y habiteront ?
Je m’intéresse aussi beaucoup aux solutions d’apprentissage par machine et des applications des données massives. La question suivante s’est naturellement posée : puis-je utiliser la télédétection et l’apprentissage par machine pour lier mes indicateurs inertes à l’écosystème qui en résulte, à grande échelle et à travers différents types d’écosystèmes ?
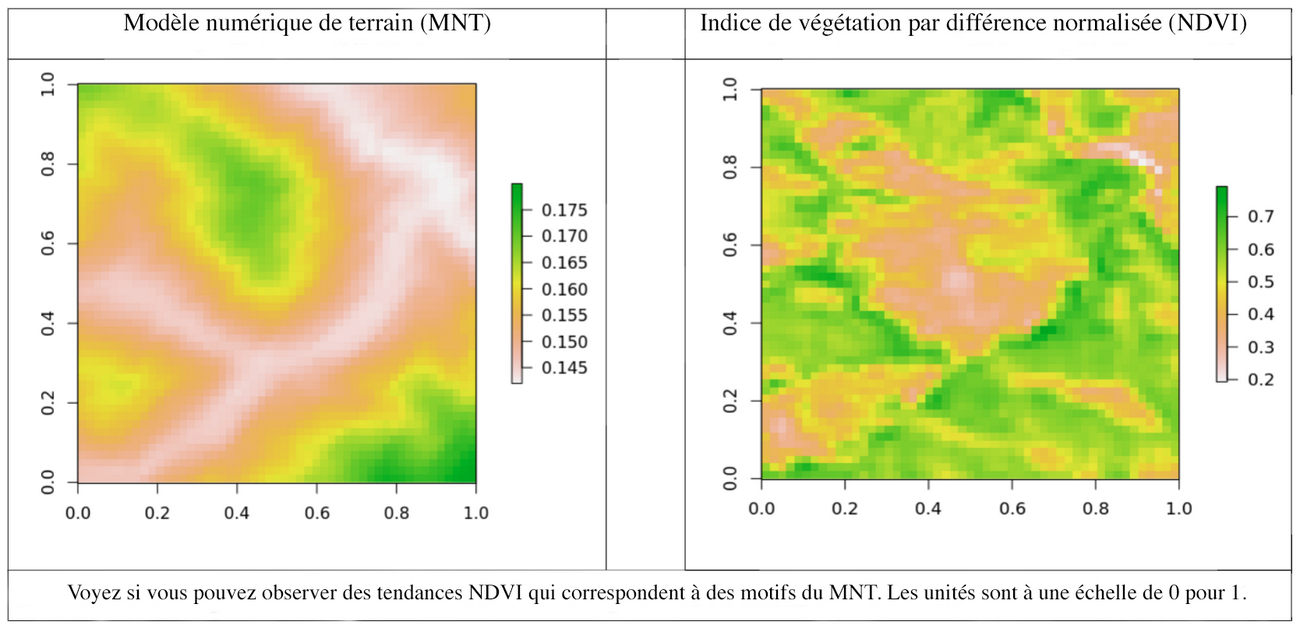
Pour se faire, j’ai dû définir mes indicateurs et variables de réponse. Afin de commencer simplement, j’ai choisi comme réponse des images NDVI de logiciel libre provenant du satellite Landsat 8, qui photographie la majorité de la planète tous les 16 jours. NDVI (ou IVDN) est un acronyme pour indice de végétation par différence normalisée, une mesure de la végétation dans une zone donnée. Par la photosynthèse, les plantes absorbent la lumière active et réfléchissent la lumière presque infrarouge, la différence entre ces deux longueurs d’onde mesure la présence de matériel de plantation sain. J’ai choisi comme indicateur un modèle numérique de terrain (MNT) et pour sa première tentative, il ignore l’activité humaine, le climat et la géochimie. Je me suis arrêtée sur une zone dont le climat ne devrait pas changer, car pour un premier essai à fabriquer le modèle, je voulais me concentrer sur les effets sur le terrain. En revanche, je voulais construire un pipeline qui allait facilement s’élargir lorsque j’allais m’attaquer à des indicateurs et des réponses plus complexes.
C’est Kubernetes qui m’a fourni la solution idéale en me permettant de créer des pods pour compléter chaque étape de mon pipeline de prétraitement puis de les supprimer lorsque je n’avais plus besoin de ces ressources.
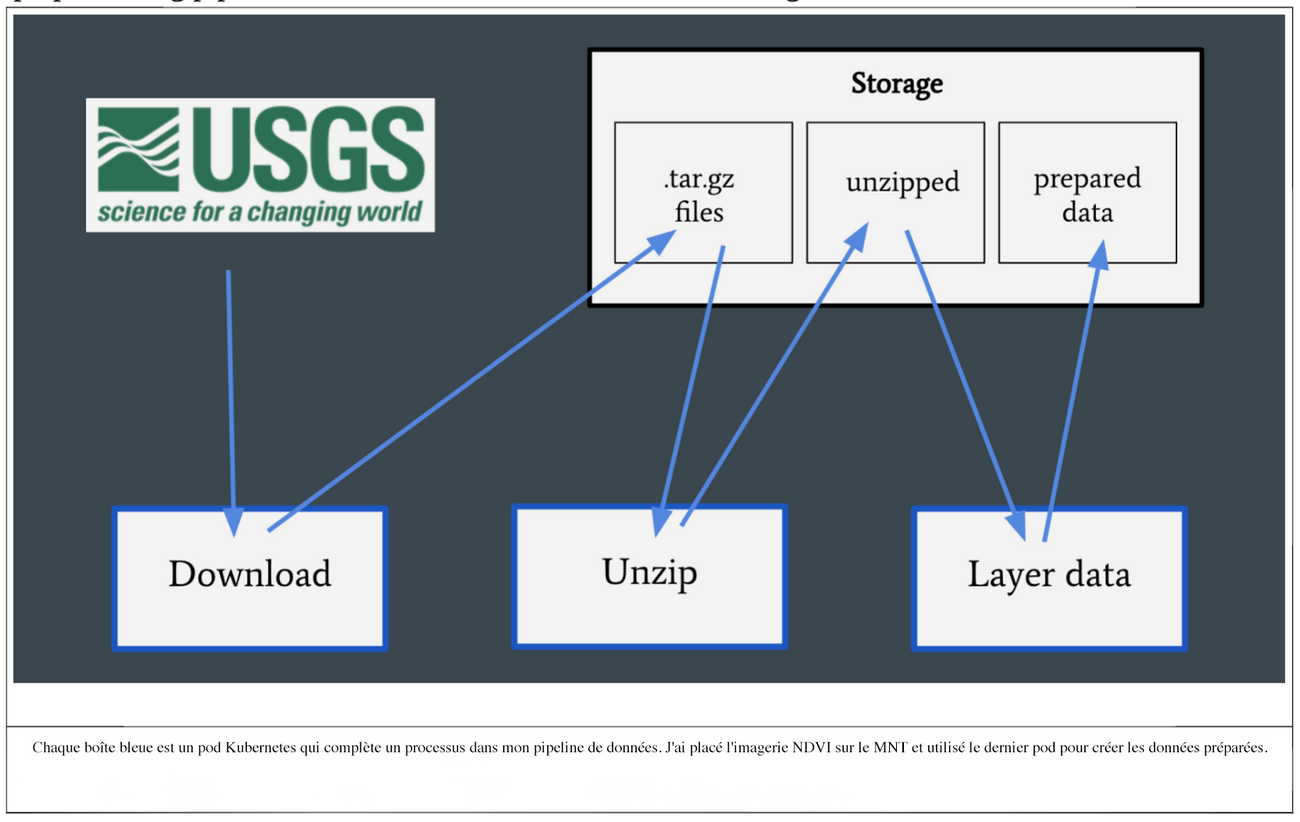
Le service géologique des États-Unis (USGS) héberge un API pour télécharger des images de Landsat 8, auxquelles j’ai accédées via le langage de programmation R, et qui ont été exécutées dans le pod de téléchargement. Les données furent alors décompressées dans un nouveau pod et finalement, mon indicateur MNT fut superposé sur l’image NDVI dans un dernier pod pour créer ma préparation de données. Cette dernière étape pourra facilement s’élargir pour se superposer à différents indicateurs selon la croissance de mon projet.
Réseaux neuronaux
L’hypothèse que je voulais tester pour cette analyse était la suivante : avec quelle précision peut-on prédire la croissance de la végétation à partir d’un MNT et ce modèle peut-il être transféré d’une zone à une autre, en présumant que le climat et autres facteurs restent les mêmes ? Pour vérifier cela, j’ai téléchargé des images NDVI provenant de deux parcs nationaux au nord des États-Unis : Parc National Salmon Challis et Parc National de Yellowstone.

J’ai choisi ces deux endroits parce qu’ils sont dans des zones géographiques similaires et donc leurs climats sont vraisemblablement similaires. Ce sont deux régions montagneuses qui couvrent à peu près la même aire de terrain. Finalement, ce sont deux parcs nationaux dont l’écosystème devrait être à l’état sauvage, relativement éloigné de l’interférence humaine (bien qu’on y retrouve quelques habitations humaines et de l’agriculture dans les deux zones).
J’ai choisi deux scènes, une provenant de Salmon Challis et l’autre de Yellowstone, de la même année et de la même saison. J’avais comme plan de créer un réseau neuronal complètement convolutif (CNN) et de l’entraîner sur les tenseurs de Salmon Challis à prédire les tenseurs de Yellowstone. En prenant des sections de 51 pixels x 51 pixels des images NDVI et MNT, j’ai crée 17 500 tenseurs individuels pour Salmon Challis et le même nombre pour Yellowstone, j’ai aussi créé un CNN qui prendrait deux entrées, le 51 x 51 MNT en plus d’un 51 x 51 pixels MNT à base résolution qui couvre une zone beaucoup plus grande, dans le cas où les caractéristiques géographiques à grande échelle autour d’une zone sont importantes pour prédire la végétation. La sortie du modèle se trouve l’image NDVI de 51 x 51 pixels.
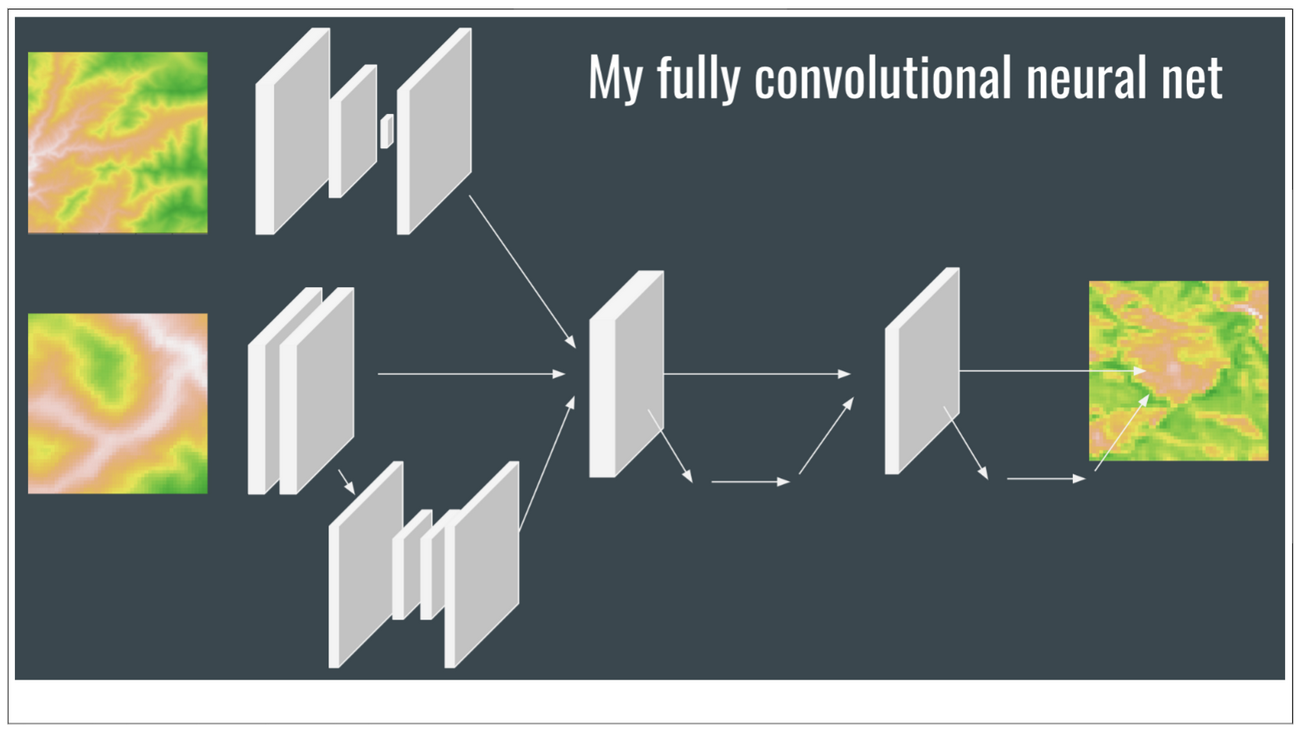
Après maints essais et erreurs, je me suis rendu compte qu’une structure de départ, inspirée par GoogLeNet, améliorait la stabilité des prévisions des modèles. La création divise les tenseurs en chemins de traitements distincts, permettant aux modèles de comprendre les différentes caractéristiques dans les données en appliquant différentes couches neuronales tout en maintenant un réseau informatiquement efficace. En 2014, GoogLeNet a remporté le défi de reconnaissance visuelle à grande échelle avec ce style d’architecture, et je recommande fortement de lire le travail de recherche original (assez accessible) pour tous ceux qui sont curieux d’en apprendre plus sur l’architecture de réseau sur la performance de réseau neuronal. Ma recherche s’est aussi inspirée de UNet, un réseau convolutif distinct.
En gros, la performance du modèle surpasse la technique classique basée sur des modèles additifs généralisés (GAM), mais reste insatisfaisante. Je voulais apprendre à concevoir des réseaux neuronaux alors pour le moment, j’évite le transfert d’apprentissage d’un réseau préentraîné même si cela reste une option. Grâce au GCP, à CloudOps et à la foule de données que la télédétection génère chaque jour, je possède les ressources et les données pour améliorer ce modèle. J’aimerais beaucoup passer encore plus d’indicateurs et augmenter la profondeur de mon réseau neuronal. Jetez un coup d’œil sur mon GitHub (le lien se trouve au début de l’article) si vous désirez voir les véritables couches dans le réseau neuronal ou encore, la solution Kubernetes utilisée pour télécharger les données. Bonne chance dans vos propres aventures dans le domaine de la science des données !
Le MNT à gauche, les tenseurs NDVI prédits pour Yellowstone au centre, les véritables tenseurs NDVI à gauche. L’exemple du haut démontre une prévision plus ou moins précise, celui du bas est très éloigné. Par contre, notons la complexité de la prévision dans l’exemple du bas. La même élévation sur la pente plus au nord ne devrait pas avoir de végétation et le modèle a enregistré des changements subtils dans l’élévation de la pente au sud, variant alors sa prédiction. Dommage que le NDVI réel ne ressemble en rien à cela.
