Le « quoi », le « pourquoi » et le « comment » des opérateurs Kubernetes

Avec la publication initiale de Docker il y a un peu plus de sept ans, notre façon d’exécuter, de construire, de maintenir et de déployer des applications a changé. L’arrivée des conteneurs logiciels a facilité l’adoption de méthodologies de développement, comme les 12-Factors App avec des concepts tels un seul code source pour plusieurs déploiements, les isolations des dépendances et l’absence de distinction entre les environnements, pour n’en nommer que quelques-uns.
Cette nouvelle philosophie de déploiement, une application par conteneur, a forcé les équipes de développement à moderniser leur façon de faire les choses, de même que la façon de conditionner leur code, ce qui a entraîné des défis :
- 1. Le nombre de conteneurs explose considérablement, ce qui complique la tâche des équipes d’opérations.
- 2. Il nous manque un élément pour orchestrer tout cela.
- 3. L’automatisation sera l’une des clés du succès.
Kubernetes à la rescousse.
En 2014, avec le lancement de Kubernetes, une structure d’orchestration dont l’objectif est de faciliter la configuration, le déploiement, l’opérationnalisation et la surveillance des conteneurs logiciels, il était facile de penser que nous étions sortis du bois et que les trois défis mentionnés plus haut étaient résolus. Kubernetes s’est rapidement démarqué comme un outil d’orchestration de choix pour lancer des applications dans des conteneurs logiciels; il devait aider les équipes d’opérations à surveiller et à maintenir les applications et permettre l’orchestration de celles-ci à grande échelle. L’automatisation est l’une des forces de Kubernetes; elle permet de lancer aisément des charges de travail qui peuvent gérer des opérations qui se répètent.
Dans un monde idéal, ceci aurait été suffisant. Si on suit la méthodologie des 12-Factor Apps, les applications sont « passives », mais puisque nous ne vivons pas dans un monde parfait, il y a toujours des exceptions. Kubernetes est excellent pour gérer des applications qui sont « passives », mais éprouve beaucoup plus de difficultés lorsque vient le temps de gérer des applications qui sont « dynamiques », comme une base de données par exemple. En effet, l’ajout, la suppression ou la mise à jour d’une instance de base de données exigent souvent des interventions manuelles, augmentant par le fait même la charge de travail de l’équipe d’opérations et les possibilités d’erreurs et contrevenant au troisième défi, l’automatisation. Alors, que faire pour lancer des applications complexes qui sont « passives » dans Kubernetes tout en relevant nos trois défis?
Le « quoi » des opérateurs.
Depuis le début, les gens cherchent à étendre les fonctions de Kubernetes et c’est de là que sont nés les opérateurs. Un opérateur est une façon de concevoir et de lancer une application dans Kubernetes en tirant parti de l’API de celui-ci. Le concept des opérateurs est de permettre l’automatisation d’applications complexes qui exigent des connaissances particulières d’un domaine, par exemple, la mise à jour d’une application avec des changements au niveau du schéma des données. L’utilisation des opérateurs élimine l’intervention humaine.
Maintenant que nous savons ce qu’est un opérateur et sa raison d’être, deux questions se posent : Quel est le « pourquoi » des opérateurs? Quel est le « comment » des opérateurs?
Le « pourquoi » des opérateurs.
D’abord, examinons les aspects du « pourquoi » et de la valeur des opérateurs. À mon avis, cinq éléments principaux sont à la base de la volonté de tirer parti des opérateurs.
1. Ils permettent d’ajouter des fonctionnalités à Kubernetes.
Les opérateurs permettent d’ajouter de la puissance à Kubernetes, principalement pour les applications qui sont « dynamiques ». Ils permettent aussi d’étendre l’API de Kubernetes sans avoir à modifier son code.
2. Les connaissances humaines sous forme de code.
Les opérateurs ont pour but de capter les connaissances humaines qui opérationnalisent les services pour les mettre en tâches répétitives. Ils permettent donc de prendre en charge le cycle de vie d’une application et d’automatiser les tâches manuelles effectuées par l’équipe DevOps.
3. La standardisation répétitive et évolutive.
Les opérateurs simplifient la façon d’exécuter une application Kubernetes en éliminant la complexité de l’infrastructure, et ce, de façon répétitive. Par exemple, pour mettre en place une copie identique (réplicas) d’une base de données PostgreSQL, plusieurs étapes doivent être suivies. Imaginez si ce processus devait être effectué des dizaines ou des centaines de fois - la tâche serait colossale et très propice aux erreurs. Les opérateurs sont là pour aider.
4. Amélioration de la résilience du système, et réduction de la charge de travail de l’équipe.
Cette affirmation nous permet d’honorer l’une des promesses des conteneurs. Ils permettent d’éviter les temps d’inactivité, allégeant le stress pour l’équipe et réduisant les erreurs, donc, par le fait même, améliorant la résilience.
5. Utilité pour les environnements multinuages et/ou les nuages hybrides.
Les opérateurs éliminent le besoin de connaître les particularités de l’environnement de l’infrastructure dans lequel il fonctionne. Un opérateur fonctionnera partout où Kubernetes est présent.
Le « comment » des opérateurs.
Évaluons maintenant le fonctionnement des opérateurs, comment les construire et comment les utiliser. Le principe des opérateurs a été construit dans le cadre de l’un des principes de base Kubernetes, la théorie du contrôleur. La fonction du contrôleur est d’apporter des ajustements en continu par l’entremise de l’API de Kubernetes pour que l’état courant reflète l’état souhaité, voir le diagramme.
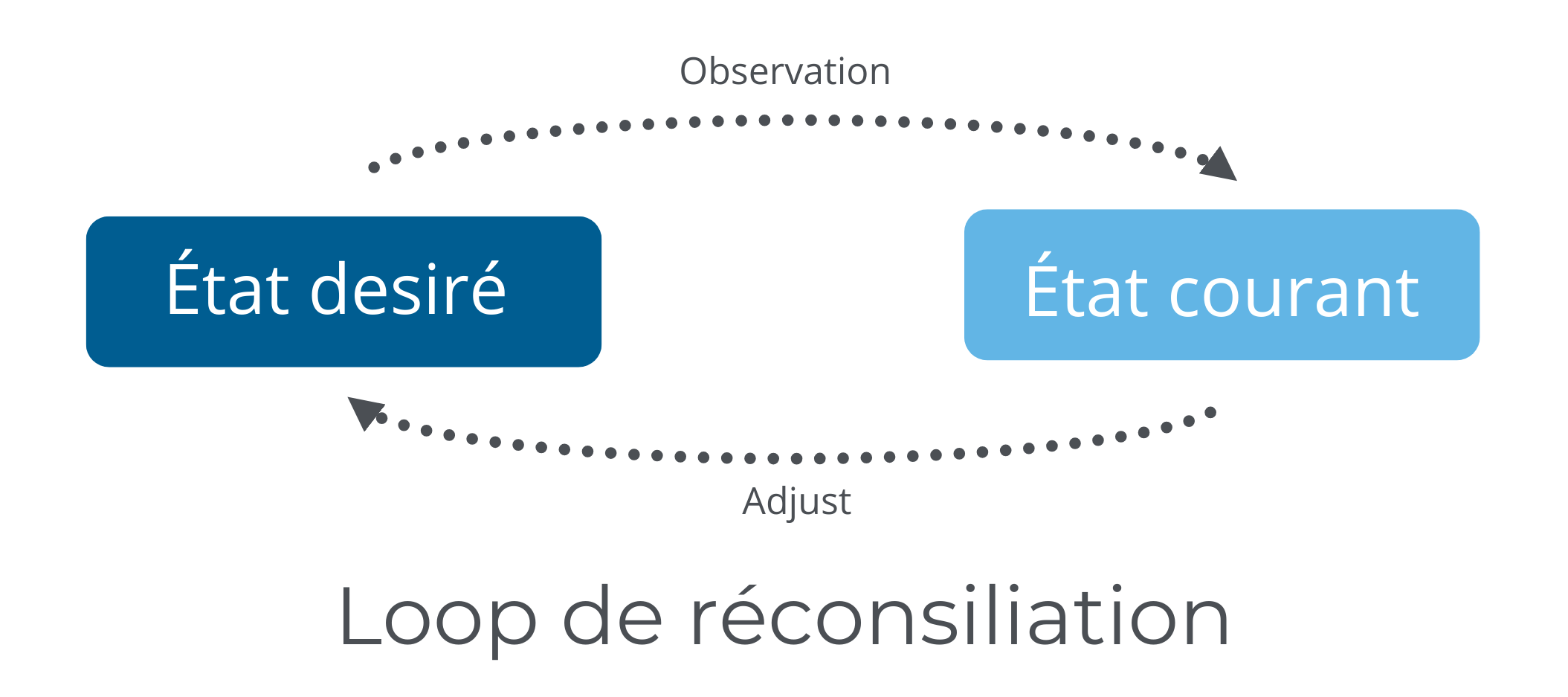
Un opérateur est donc un contrôleur spécifique à une application Kubernetes. Il permet d’étendre l’API de Kubernetes dans le but de créer, de configurer et d’opérationnaliser des applications complexes sans intervention humaine. Pour ce faire, il tire parti des ressources personnalisées qui sont une extension de Kubernetes, laquelle permet de stocker et de récupérer de l’information pertinente sur l’état souhaité.
Un opérateur comprend quatre éléments importants.
- 1. Des ressources personnalisées.
- 2. Le code du contrôleur qui exécute la boucle sur le plan de contrôle.
- 3. Une image du conteneur qui contient le code de l’opérateur.
- 4. Un déploiement qui assure l’exécution d’un pod avec le conteneur.
Deux options s’offrent à nous pour l’utilisation des opérateurs : créer notre propre opérateur, ou utiliser un opérateur existant. Par exemple, l’opérateur Prometheus, probablement l’un des opérateurs les plus connus. Grâce à cet opérateur, il est maintenant plus facile pour les équipes DevOps d’installer Prometheus dans leur cluster Kubernetes pour surveiller leur application. Mais que se passe-t-il lorsqu’il n’y a pas d’opérateur existant pour notre scénario? Comment pouvons-nous construire nos propres opérateurs?
Différentes options sont envisageables pour aider à construire un opérateur comme Kudo et KubeBuilder, mais je suggère d’utiliser Operator Frameworks.
Operator Frameworks est une trousse d’outils de logiciel libre créée pour aider à construire des opérateurs et prendre en charge les différentes phases de conception, d’opérationnalisation et de découverte des opérateurs. Voici les trois composantes d’Operator Frameworks et leur fonction.
Operator SDK permet au développeur de construire un opérateur en se basant sur son expertise sans nécessiter des connaissances approfondies sur l’API de Kubernetes. Il fournit les outils requis pour construire, tester et conditionner un opérateur, de même que l’échafaudage et le code générique requis pour amorcer rapidement un nouvel opérateur.
Operator LifeCycle Manager OLM complémente Kubernetes et fournit une façon déclarative d’installer, d’opérationnaliser et de mettre à jour un opérateur. Il s’exécute sur le cluster Kuberenetes et apporte des fonctionnalités intéressantes, dont la mise à jour automatique et la vérification des dépendances.
Operator Hub est un endroit où la communauté de Kubernetes partage des opérateurs. Ceci permet d’utiliser des opérateurs qui sont déjà en place. Parmi les plus connus se trouve Prometheus Operator. L’operator Hub est accessible ici
En résumé, les opérateurs sont des moyens de combler les lacunes de Kubernetes en complémentant son API afin de permettre le développement d’applications complexes et « dynamiques » qui fonctionneront sur n’importe quelle infrastructure Kubernetes. Ils permettent d’implanter plusieurs applications en continu tout en respectant les meilleures pratiques.
Souhaiteriez-vous apprendre sur les outils et les pratiques DevOps du confort de votre foyer ? Modernisez le bassin de compétences de votre équipe technique en l'inscrivant à notre prochain atelier pratique de trois jours sur Docker et Kubernetes
