Opérateurs Kubernetes 101

La plupart des applications nécessitent des ressources qui proviennent des environnements dans lesquels elles opèrent, comme de la mémoire, UCT, stockage, réseautage, etc. Selon l’application, beaucoup de ces ressources seront consommées facilement et de façon transparente, mais pas toutes. La majorité des applications doivent avoir été en partie préalablement configurées avant d’être déployées et auront ensuite besoin d’entretien particulier relativement aux sauvegardes, aux restaurations, aux compressions de fichiers, aux vérifications de haute disponibilité, au maintien de journaux, à la croissance de base de données, aux routines de bilan de santé, etc. Elles devront possiblement être mises dans un état spécial pendant la mise à jour pour s’assurer, par exemple, qu’elles ne laissent pas tomber les utilisateurs.
Toutes les choses mentionnées ci-avant décrivent les connaissances techniques humaines que l’on applique par-dessus une application. Tout ce labeur opérationnel se répète maintes fois au cours du cycle de vie d’un logiciel en fonction. Souvent, on utilise des scripts pour automatiser ces tâches. Qu’arrive-t-il si une application vit et croît dans un conteneur, dans un pod orchestré par Kubernetes et OpenShift? Existe-t-il une meilleure façon de tout automatiser? Quelque chose qui pourrait «rendre possibles les systèmes à couplage lâche qui sont souples, gérables et observables ; et lorsque combiné avec une automatisation solide, cela permet aux ingénieurs d’effectuer des changements importants fréquemment et de façon prévisible avec un minimum d’efforts»? (Tiré de la définition de Cloud Native)
La réponse à cette question est le modèle « opérateurs ». On les appelle également opérateurs Kubernetes. Que sont-ils? Comment en développer un? Qu’ajoutent-ils à nos applications? Qu’ajoutent-ils à notre expérience de logiciel en tant que service lorsqu’ils sont publiés sur un noyau opérateur?
La meilleure définition que j’ai à donner est la suivante : un opérateur est une extension de l’api Kubernetes qui prend la forme d’une ressource personnalisée, conciliée et gérée par un contrôleur standard exécutant un pod hors déploiement. Cela semble compliqué n’est-ce pas? Voyons voir toutes les parties :
Accroître l'Api Kubernetes
Avant tout, prenons un peu de recul pour essayer de comprendre élément par élément. La première question à se poser est: comment interagissons-nous avec Kubernetes? Nous utilisons kubectl pour déployer et maintenir notre application d’un point de vue admin autonome, nous utilisons « client-go » et d’autres bibliothèques pour automatiser la communication avec l’Api Kubernetes. OK parfait. Que nous apporte l’API?
Jetons un œil à ce que nous apporte L’API Kubernetes:
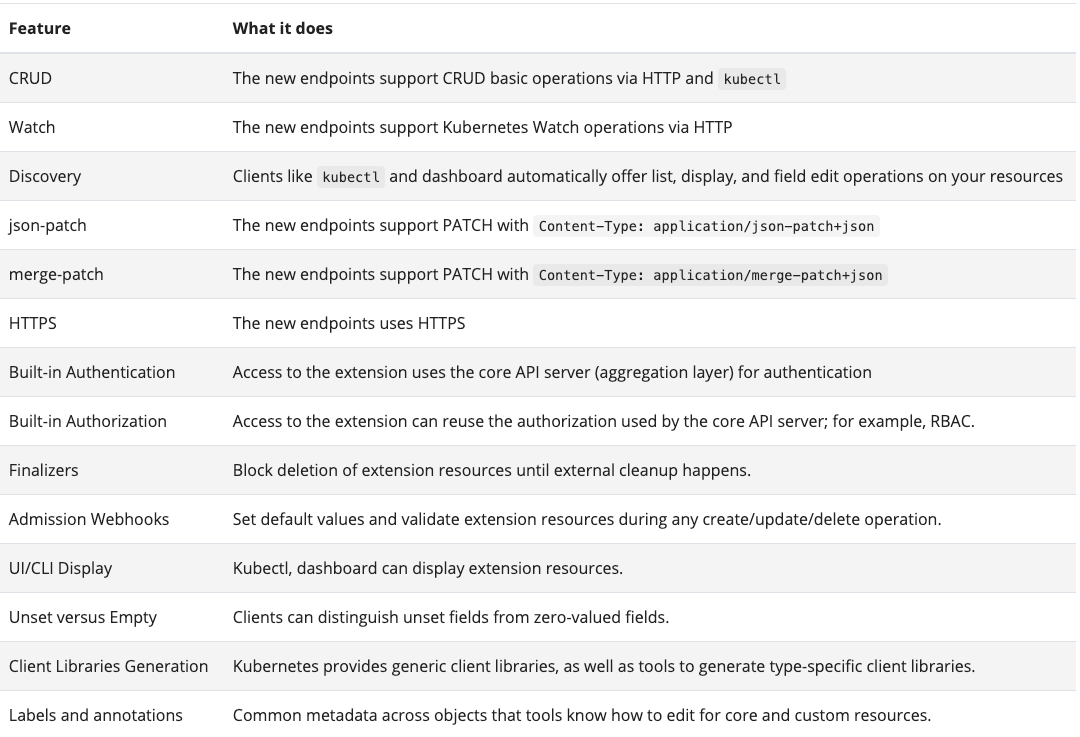
Toutes ces fonctionnalités sont partagées entre les objets Kubernetes natifs. De nombreuses opérations bien conçues telles que créer, lire, mettre à jour et supprimer, la capacité de surveiller les extrémités, l’authentification et l’autorisation et plus encore.
Nous savons que les ressources Kubernetes sont bâties sur des définitions qui proviennent de l’API Kubernetes canonique qui se trouve dans ce répertoire: https://github.com/kubernetes/api
Et c’est là que nous trouvons les groupes, les versions et les types pour ces ressources, n’est-ce pas? C’est l’information qui s’en va directement dans le champ appelé TypeMeta. Jetons-y un coup d’œil!
Si l’on prend une ressource comme un DaemonSet et qu’on lance:
$ kubectl get DaemonSet myDS -o yamlTout au début, nous verrons quelque chose comme ceci:
apiVersion: apps/v1
kind: DaemonSetCela nous indique que les DaemonSets sont sous le groupe apps, ont la version v1, et sont un type de DaemonSet. Et où pouvons-nous trouver le type golang correspondant pour cet objet? Nous n’avons qu’à naviguer dans ce répertoire pour trouver le fichier types.go. Comme ceci:
$ tree -L 2
...
├── apps
│ ├── OWNERS
│ ├── v1
│ ├── v1beta1
│ └── v1beta2
...
Dans le dossier v1, nous avons types.go et nous pouvons chercher pour le Type DaemonSet comme ci-dessous :
type DaemonSet struct {
metav1.TypeMeta `json:",inline"`
// Standard object's metadata.
// More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
// +optional
metav1.ObjectMeta `json:"metadata,omitempty" protobuf:"bytes,1,opt,name=metadata"`
// The desired behavior of this daemon set.
// More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status
// +optional
Spec DaemonSetSpec `json:"spec,omitempty" protobuf:"bytes,2,opt,name=spec"`
// The current status of this daemon set. This data may be
// out of date by some window of time.
// Populated by the system.
// Read-only.
// More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status
// +optional
Status DaemonSetStatus `json:"status,omitempty" protobuf:"bytes,3,opt,name=status"`
}
Et si nous pouvions ainsi développer notre application comme si elle faisait partie intégrante de Kubernetes (Kubernetes native) ou du moins tirer profit de toutes les fonctionnalités en tapant simplement kubectl get myapplication pour recevoir de l’information selon mes besoins spécifiques? Et plus encore, si nous pouvions créer nos propres routines et fonctions de mises à niveau? Et si nous pouvions tirer avantage des métriques intégrées et bâtir une compréhension profonde de Kubernetes de la même manière que nous le faisons pour les ressources natives?
Les formidables fonctionnalités qui partagent toutes ces bonnes choses qu’offre Kubernetes sont les ‘ressources personnalisées’ et les ‘définitions des ressources personnalisées’. Elles agissent environ de la même façon que les DaemonSets natifs que nous avons vus auparavant. Ce sont des extensions de l’Api Kubernetes qui nous permet de créer nos propres champs afin de concevoir la structure de données parfaite pour représenter nos besoins en application. Cela nous permet d’avoir notre propre groupe, versions et sorte d’api.
Ici vous pouvez en apprendre plus sur les modules d’extension CRD et API. À ce stade-ci, nous en sommes qu’à mi-chemin. Que doit-on ajouter pour activer ces ressources personnalisées? Le contrôleur. Voyons voir!
Contrôleurs : Les rendre Kubernetes Native
Les contrôleurs ne sont rien d’autre qu’une boucle. L’idée est une boucle de contrôle qui vérifie l’état d’une ressource pour chaque itération. Après avoir vérifié, en lisant, l’état de la ressource voulue, la boucle de contrôle lance ce que l’on appelle la fonction ‘reconcile’ qui compare l’état actuel avec l’état attendu de cet objet. C’est la façon normalisée selon laquelle fonctionne Kubernetes.
Donc, si nous avons défini notre propre objet personnalisé pour représenter notre application, avec tous les champs et les structures de données requises, la pièce qui suit est le contrôleur avec la fonction ‘reconcile’. Cela nous donne le contrôle véritable de l’état de notre application en exécutant une logique personnalisée qui intègre ce dont nous avons discuté auparavant : la connaissance opérationnelle humaine.
Si vous désirez en apprendre davantage, cliquez ici.
Opérateur SDK : Bâtir et initialiser
Ce n’est pas une tâche facile que de comprendre les rouages de l’API Kubernetes, conformément aux normes OpenApi. On peut dire la même chose à propos de la création de contrôleurs qui fonctionnent exactement comme les natifs avec tous les outils fournis par le signal de la machinerie API et les bibliothèques de contrôle de temps d’exécution, afin de faciliter la création des structures de l’opérateur. Parmi les outils fournis par la structure de l’opérateur, on trouve l’outil de ligne de commande operator-sdk. Voyons voir comment cela nous aide à rapidement échafauder tous les outils nécessaires afin de se concentrer uniquement sur la logique de l’opérateur.
Initialisation d’un nouveau projet opérateur :
$ mkdir myproject
$ cd myproject
$ operator-sdk init --domain mydomain.com --group myapp --kind MyApp --version v1alpha1
Après avoir été lancé, un dossier de projet go sera échafaudé avec un minimum d’éléments pour développer et bâtir l’opérateur.
.
├── Dockerfile
├── Makefile
├── PROJECT
├── bin
├── config
├── go.mod
├── go.sum
├── hack
└── main.go
Nous avons notre Dockerfile de base pour bâtir l’opérateur, un Makefile avec toute l’automatisation nécessaire pour tester et bâtir, le dossier de configuration ‘config’ où se trouvent tous les artéfacts yaml propulsés par Kustomize et le main.go où tout commence avec le gestionnaire qui lance nos contrôleurs. Pour ajouter une nouvelle extrémité API/CRD avec un contrôleur pour notre application personnalisée, nous lançons l’exemple suivant:
$ operator-sdk create api \
--group=myapp \
--version=v1alpha1 \
--kind=MyApp \
--resource \
--controller
Nous avons maintenant deux nouveaux dossiers:
.
├── Dockerfile
├── Makefile
├── PROJECT
├── api
├── bin
├── config
├── controllers
├── go.mod
├── go.sum
├── hack
└── main.go
Les dossiers api et contrôleurs. Et c’est là que nous trouvons tout le code automatiquement généré pour commencer le processus de développement.
Dans l’api, nous trouvons :
$ tree -L 2 api
api
└── v1alpha1
├── groupversion_info.go
├── myapp_types.go
└── zz_generated.deepcopy.go
myapp_types.go will hold all the fields and elements for the application.
And finally on the controller side we have:
$ tree -L 2 controllers
controllers
├── myapp_controller.go
└── suite_test.go
myapp_types.go renfermera tous les champs et les éléments pour l’application.
Et finalement, dans le dossier contrôleur, nous avons:
func (r *MyAppReconciler) Reconcile(req ctrl.Request) (ctrl.Result, error) {
_ = context.Background()
_ = r.Log.WithValues("myapp", req.NamespacedName)
// your logic here
return ctrl.Result{}, nil
}
Afin de mieux comprendre ce processus si vous désirez plonger, je recommande fortement ces deux tutoriels :
Le livre ‘Kubebuilder’. Kubebuilder a fusionné dans l’operator-sdk et une bonne partie de sa logique provient du projet kubebuilder, alors pour avoir une meilleure compréhension de l’api Kubernetes et de la logique des contrôleurs, c’est probablement le meilleur endroit où commencer.
Finalement, je recommande fortement de jeter un œil au site Internet operator-sdk où vous trouverez également des tas de ressources et d’exemples. https://sdk.operatorframework.io
Gestionnaire du cycle de vie d'un opérateur : publier des opérateurs
Un autre projet important dans la structure ‘operator’ est le gestionnaire de cycle de vie d’un opérateur ; il agit comme un catalogue de logiciels présentant à Kubernetes une application de logiciel en tant que service d’où peuvent être installés tous les opérateurs publiés de façon publique. Jetez un œil au projet ici et pour plus d’informations sur le https://operatorhub.io.
Conclusion
Nous avons discuté de ce que sont les opérateurs Kubernetes et du fait qu’ils sont composés de deux pièces élémentaires, mais puissantes qui sont les ressources Kubernetes personnalisées et les contrôleurs. Nous avons quelque peu abordé l’operator-sdk qui nous aide à échafauder tout le code afin de commencer facilement à développer des applications Kubernetes natives qui interagiront avec l’API pour contrôler les ressources personnalisées qui représentent notre application dans le cluster. Nous avons suggéré de jeter un œil sur le livre Kubebuilder et sur les documents operator-sdk sur le site Internet. Finalement, nous avons soulevé que le gestionnaire de cycle de vie est le catalogue officiel où l’on peut retrouver tous les opérateurs publics.
 Alexandre Menezes
Alexandre Menezes
Alexandre Menezes travaille chez Red Hat comme ingénieur de fiabilité de service et aide les partenaires et les clients à développer leurs opérateurs afin de faire reluire leurs applications à travers tous les écosystèmes de conteneurs.
