Les entrées Kubernetes ne sont pas aussi difficiles qu’on le croit: utilisez les entrées pour acheminer vers vos services

Comment utiliser les entrées pour acheminer vers vos services Kubernetes
Si vous utilisez Kubernetes, vous avez probablement des déploiements ou des ensembles à états qui gèrent un certain nombre de « pods » exploitant différents microservices à l’intérieur d’une application. Cela ne sert à rien si vos microservices ne peuvent pas communiquer entre eux. Ils sont exécutés comme de nombreux « pods » planifiés par Kubernetes et ces « pods » ont des adresses IP et des noms kubedns assignés qui sont trop changeables pour que l’on puisse s’y fier pour le réseautage. Lorsque les « pods » meurent, leurs adresses IP et leurs noms sont réassignés (sauf pour les ensembles à états dont le nom de domaine est statique). Dans la documentation Kubernetes, les services sont décrits comme des abstractions qui « définissent un ensemble logique de « Pods » et des règles à suivre pour y accéder. » Concrètement, cela signifie qu’un déploiement configurera une étiquette décrivant le nom de l’application sur les « pods » qu’elle crée et en créant une ressource de service, le créateur utilisera les étiquettes comme des sélecteurs afin de grouper tous les « pods » exécutés sur une application donnée. Ces services permettent à ceux qui veulent accéder aux applications de ne pas avoir à surveiller ce qui est exécuté sur chacun des « pods » et de n’avoir qu’à préciser l’application à laquelle ils désirent accéder.
Le réseautage entre les ressources Kubernetes a plusieurs facettes différentes. De multiples ressources peuvent communiquer de l’intérieur d’une grappe Kubernetes. KubeDNS et clusterIPs sont parfaits pour lier les services internes afin qu’ils communiquent ensemble sans exposer le service au monde extérieur.
Voici un survol de quelques concepts de réseautage Kubernetes dont vous aurez besoin pour exploiter vos services sur Kubernetes.
ClusterIP – une adresse IP unique qui se réfère à votre service et qui n’est utilisable que de l’intérieur d’une grappe.
Nodeport – Utilisé pour communiquer là où le « pod » d’un déploiement est exécuté avec une adresse ayant la forme,
KubeDNS – KubeDNS n’est pas tant un type de service qu’une façon intégrée de communiquer avec un service donné de façon interne. Avec KubeDNS, vous pouvez faire communiquer les « pods » sans associer une application à un service.
Équilibreur de charge – Crée un équilibreur de charge externe dans le nuage actuel (s’il est soutenu) et assigne au service une adresse IP externe fixe.
ClusterIP et KubeDNS simplifient les communications entre les services. Mais quoi faire si l’on veut exposer l’application au monde extérieur ? Sauf pour les essais, Nodeport est en lui seul, un mauvais choix. La planification de Kubernetes ne garantit pas que les « pods » vont toujours être exécutés sur les mêmes nœuds, car seuls les fournisseurs infonuagiques peuvent faire en sorte qu’une adresse IP unique soit liée à votre dns.
Les contrôleurs d’entrées Kubernetes sont des équilibreurs de charge de couche 7 exécutés sur Kubernetes même ! Cela signifie qu’aucun fournisseur infonuagique ne fournit le lien entre un API Kubernetes et un équilibreur de charge. Pour certaines architectures, on utilisera toujours un équilibreur de charge externe. On y reviendra plus tard. L’équilibreur de charge lui-même est exploité sur Kubernetes et l’entrée gère l’accès externe aux services dans une grappe. À la base, il s’agit d’une collection de règles qui permettent au trafic entrant d’atteindre les services de la grappe. Même si elle n’a pas toutes les fonctionnalités d’un équilibreur de charge, elle répond aux mêmes besoins et son déploiement est beaucoup plus facile et rapide. En fait, elle est si bien rangée qu’elle permet, par une seule commande, l’installation d’un nouveau routage à partir du routage de la couche 7 sur votre terminal. Si cela fonctionne comme il faut, vous n’aurez plus à vous préoccuper de l’installation d’un équilibreur de charge et la livraison de l’application se fera de façon autonome et bien rangée.
Les services agissent comme une colle entre un ensemble de « pods » connectés logiquement et qui sont exposés principalement comme des adresses IP dont on peut faire un routage à l’interne. Les entrées Kubernetes servent de colle entre les règlements et les services relatifs aux entrées. Ces règlements sont une combinaison de noms d’hôtes et de noms de chemins.
Voici un survol de quelques architectures potentielles utilisant l’entrée pour acheminer vers vos services.
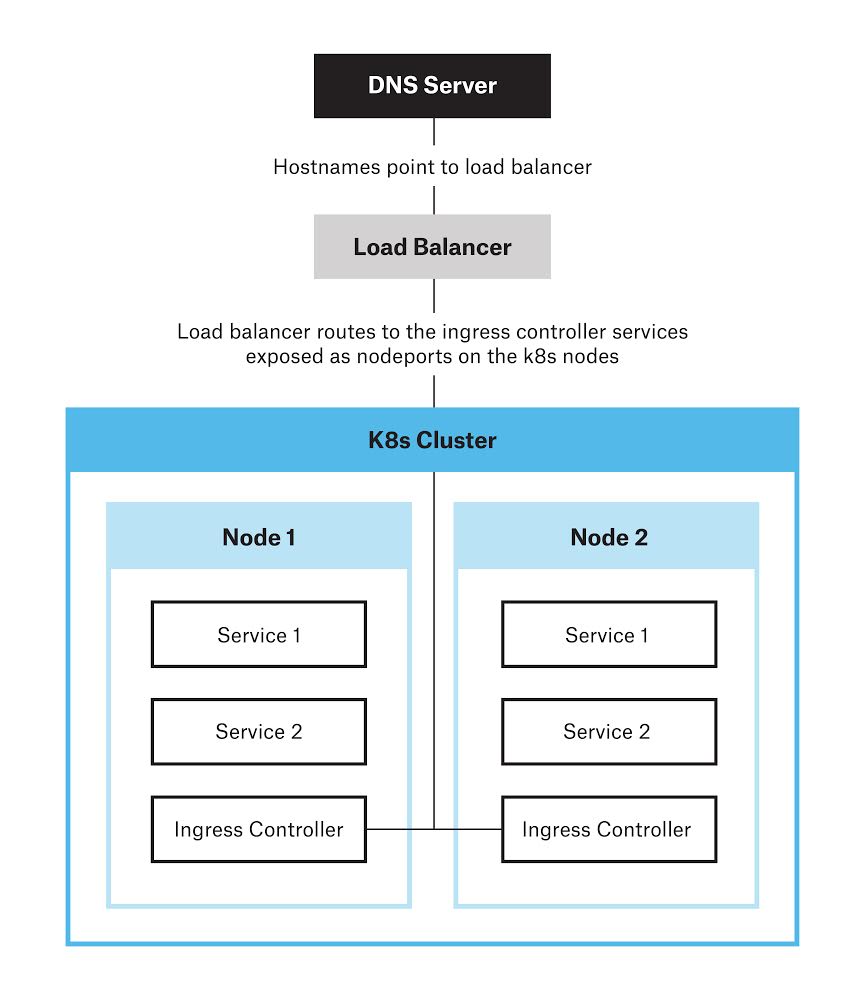
L’architecture ci-dessus inclut l’exécution d’un contrôleur d’entrée en tant qu’ ensemble daemon, c’est une ressource qui assure que chaque nœud exécute une copie d’un « pod » donné. Ces contrôleurs d’entrée sont exposés en tant que nodeport, un équilibreur de charge effectue le routage du trafic vers les contrôleurs d’entrée qui à leur tour, acheminent le trafic vers les services et les backends appropriés.
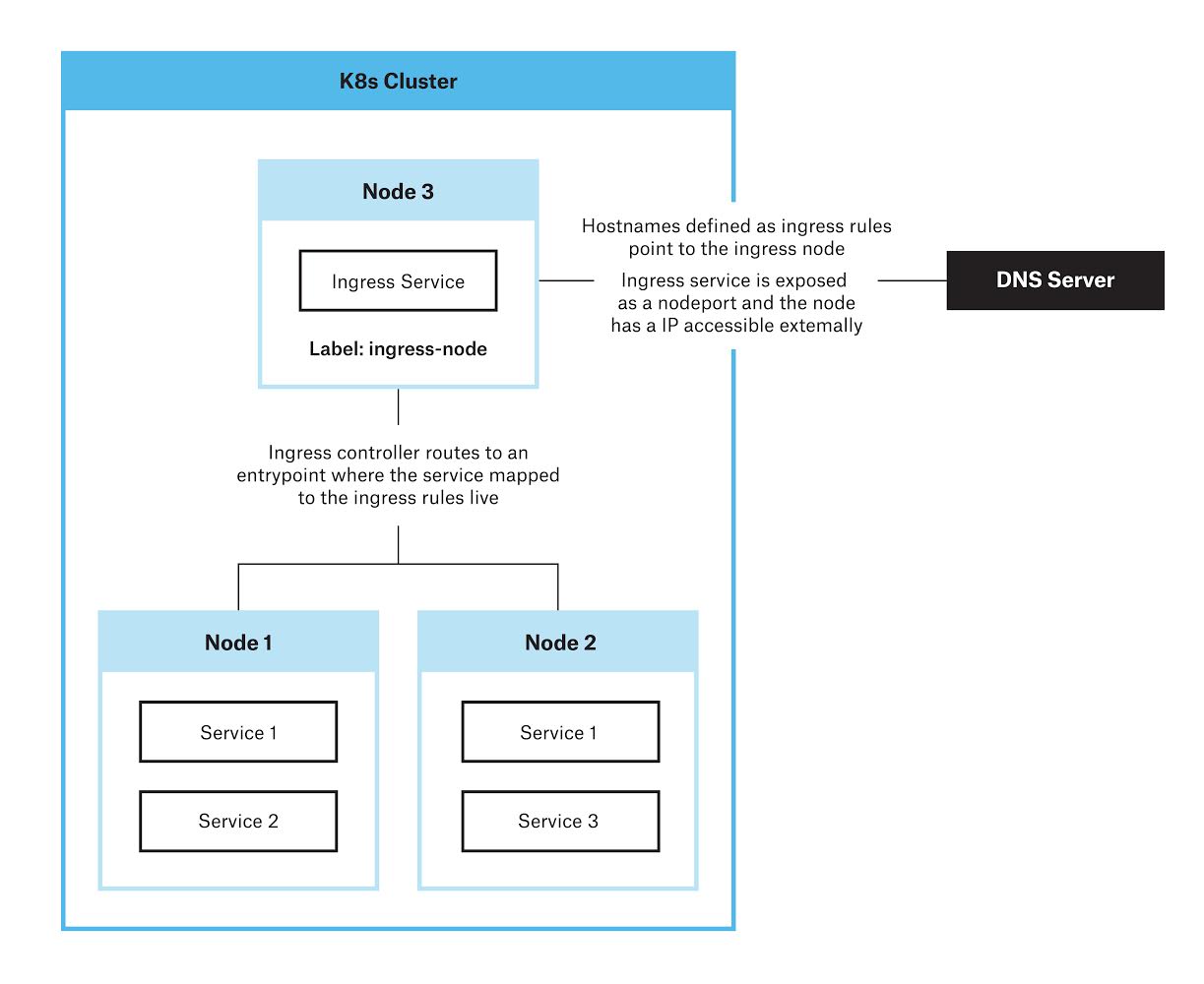
L’architecture ci-dessus implique d’avoir un nœud Kubernetes réservé où seul le contrôleur d’entrée est planifié et achemine tout le trafic externe directement vers ce nœud.
Comment déployer des entrées sur un déploiement Kubernetes de type vanille
Le fait d’exécuter vos propres grappes vous accorde un meilleur contrôle sur la configuration. Par exemple, vous pouvez choisir n’importe quelle classe de stockage voulue au lieu que votre fournisseur infonuagique vous en impose une. Vous pouvez aussi changer de fournisseur d’entrée tout en restant attaché à l’écosystème. En tant que ressources Kubernetes, les entrées sont des fournisseurs de code de logiciel libre qui permettent la communication entre les « pods » Kubernetes. Ils ont tous la même interface mais viennent en plusieurs formes différentes. Exécuter les entrées sur votre propre grappe demande plus de temps et d’expertise mais offre plus de flexibilité afin de personnaliser vos propres déploiements. Que vous exécutiez vos « pods » Kubernetes comme ensembles daemon ou encore là où seul le contrôleur d’entrée est planifié, comprendre et mettre en œuvre la meilleure architecture améliorera les communications entre vos microservices.
Étapes à suivre
Suivez cette courte marche à suivre pour créer une entrée exécutée sur un nœud étiqueté. Nous présumons que vous avez accès à une grappe k8s exécutée. Cette entrée redirige automatiquement de http vers http ; nous présumons que vous avez des certificats pour les noms d’hôtes vers où vous voulez effectuer le routage mais pour des certificats gratuits, essayez letsencrypt.
Étape 1 – Étiquetons le nœud qui deviendra le nœud entrant
kubectl label nodenode-role.kubernetes.io/ingress=true
Étape 2 – Créons un namespace appelé ingress-demo d’où nous exploiterons le contrôleur d’entrée.
kubectl create ns ingress-demo
Pour le reste de la marche à suivre, nous allons changer notre contexte kube config’s pour le namespace suivant :
kubectl config set-context $(kubectl config current-context) --namespace=ingress-demo
Étape 3 – Installons notre contrôleur d’entrée. Cela devrait exécuter notre nœud d’entrée et être responsable de la lecture des types de ressources d’entrée et du routage adéquat des noms d’hôtes. Si l’on crée des ressources d’entrée sans avoir un contrôleur d’entrée sur notre grappe, il ne se passera rien. Il existe une variété de contrôleurs d’entrée qui peuvent être utilisés par K8s, Kubernetes offre le soutien et le maintien des contrôleurs GCE et nginx controllers, mais pour les besoins de cette présentation, nous utiliserons le contrôleur Traefik.
Pour le soutien HTTPS nous devons premièrement installer un secret ssl vers Traefik pour que notre déploiement puisse le lire. Cela créera un secret appelé ingress-cert
kubectl create secret tls ingress-cert --cert <./path-to-cert> --key <./path-to-key>
Installons une configmap que le déploiement montera comme un volume qui soutiendra la configuration traefik.
kubectl create cm traefik-ingress-cm --from-file=./traefik-ingress.toml
Nous allons devoir aussi créer des rôles adéquats pour que notre entrée puisse lire les ressources à travers les namespaces.
kubectl create -f ./ingress-rbac.yaml
Nous sommes maintenant prêts à créer notre déploiement !
kubectl create -f ./ingress-deploy.yaml
Si vous effectuez un « kubectl get pods » vous devriez maintenant voir un pod traefik-ingress-deployment exécuté. Vous pouvez dorénavant créer des ressources d’entrées qui lient le routage vers vos services. N’oubliez pas de changer vos serveurs DNS ou votre fichier hôte pour qu’il pointe vers le nœud d’entrée.
Le repo est ici.
Si vous voulez en apprendre davantage, inscrivez-vous à notre atelier pratique de trois jours sur la conteneurisation d’applications avec Docker et Kubernetes.
 Evan M.
Evan M.
Evan M. est un programmeur qui habite et qui travaille à Montréal. Dans ses temps libres, il aime s’occuper des chiens, amener sa grand-mère au restaurant et faire du vélo toute l’année. Evan est développeur infonuagique chez CloudOps et se passionne pour tout ce qui est Kubernetes.
